Google Search Console index reports are a feature that allows you to track the indexing status of your websites, and see coverage errors affecting the indexing processes.
Through the Search Console Index reports, you can follow the processes related to your Sitemaps and perform URL removal operations.
How to Access Google Search Console Index Reports?
- Open Google Search Console
- Enter the property where your website is registered
- Index reports are located in the left management panel.
- Three separate features, Coverage, Sitemap, and URL Removal, are located under the index reports tab.
What Does the Google Index Reports Section Include?
The index coverage reports located on the Google Search Console panel include three different sections. These sections are:
- Coverage
- Sitemaps
- URL Removal
These three features directly affect the index status of websites. They provide direct information about the index errors of websites. Now, we can examine these three features in index reports one by one.
Google Search Console Coverage Reports
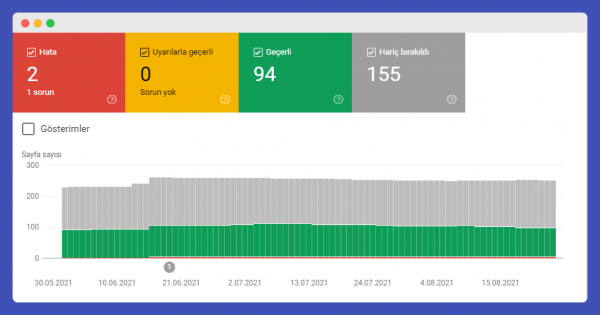
Google Search Console Coverage Reports provide vital information on behalf of websites under the index reports section of the Search Console. They allow you to see how all URLs on your site are perceived by Google and whether they are included in the coverage. There are four different categories within the coverage reports:
- Error
- Warning
- Valid
- Excluded
These categories explain the status of your URLs in the eyes of Google, whether they appear in search results or not, and if not, why they do not appear. They directly affect your digital visibility and shed light on reasons for losing organic traffic or situations where you do not receive an index.
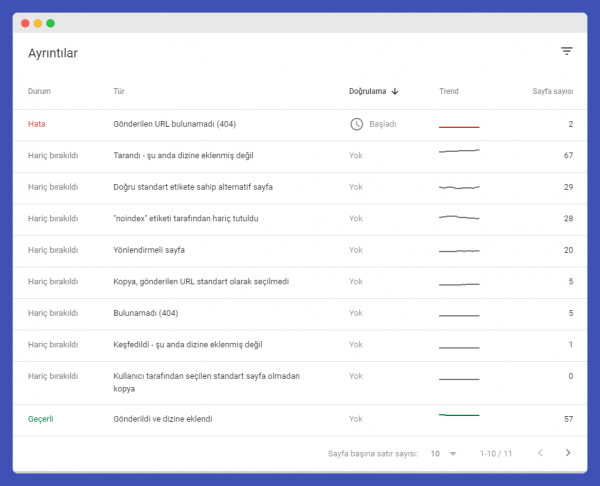
Google Search Console Coverage Errors
Search Console coverage errors show URLs on your website that do not appear in search results due to some errors. Coverage errors can appear in multiple forms. As indicated in the Google guide, there can be 9 different types of coverage error situations.
For detailed information about coverage errors, another resource is: https://support.google.com/webmasters/answer/7440203
Server Error (5xx)
A server error indicates that Google’s bots tried to access your URLs but encountered a server-related error during the process. This situation is usually temporary. A momentary server error can appear as a coverage error. It’s important to check and verify.
Solution suggestion: This situation may be due to a momentary server malfunction. Server logs can be checked. Actions can be taken on the server to ensure the error does not continue.
Redirect Error
A redirect error usually occurs when a URL is redirected multiple times to another URL, creating a redirect chain. Additionally, redirect loops or empty URL redirects can also cause this error.
Solution suggestion: To break redirect chains, make sure you are redirecting between no more than two different URLs. Do not redirect URL A to URL B and then URL B to URL C. Also, do not choose two different target URLs for a URL you will give a 301 code to.
URL Blocked by Robots.txt
This error indicates that some URLs cannot be indexed due to the rules used in your Robots.txt file. If the URLs presented under this report are intentionally blocked by you, there is no problem.
Solution Suggestion: If these blocking situations were not done intentionally, it’s a critical error that needs immediate resolution. Make sure the URLs you have blocked with Robots.txt rules are not presented to Google via the sitemap. URLs blocked in Robots.txt should also not appear in internal links.
URL Marked as Noindex
The noindex error in the coverage report shows that some of your URLs are tagged with the noindex label, preventing them from being indexed. If the URLs under this report are intentionally presented to Google with a noindex tag, there is nothing to worry about. However, if these URLs should be indexed and are receiving such an error, immediate action is required.
Solution Suggestion: Check the URLs to ensure they are not mistakenly tagged with noindex. If you are using a noindex tag for a URL, make sure these URLs are not included in the sitemap.
URL Appears as Soft 404
Soft 404 is a type of page that returns a 200 (successful) status code but actually indicates to the user that the page does not exist. Because it returns a successful status code, search engines do not recognize this page as a 404 page. In the Soft 404 Detected report, you can view such pages if you have them.
Solution Suggestion: Verify whether the URLs indeed return a 200 status code. If such a situation exists, you must ensure these pages return a 404 code. Addresses that are not found or have been removed from the site should definitely return a 404, not a 200 code.
URL Appears as Unauthorized Request 401
The 401 error code is an HTTP error code indicating that the necessary permissions/authorizations to access the page are lacking. It signifies that the page can only be viewed by individuals with the necessary permissions. If you see this error on Google Search Console, you should determine how bots are reaching these pages that return a 401 code.
Solution Suggestion: Scan your site for internal links. If page addresses that return a 401 error are used in internal links, remove those links. Ensure such URLs are not included in the sitemap.
URL Not Found 404
The 404 coverage error occurs when Google receives an index addition request for URLs on your site that return a failed (404) error code. These index requests might have been sent via your sitemap, or Google might have reached these non-existent URLs through internal links on your site.
Solution Suggestion: Examine each URL listed under this report, subject them to redirection processes, and create requests for removal from the index. Ensure you are not using these URLs in internal linking processes and that they are not included in your sitemaps.
URL Returns a 403 Error
The 403 coverage errors emerge when some URLs on your site are absolutely forbidden from access. It indicates that Googlebots tried to access these URLs but could not index them due to the access ban. You should individually examine these URLs to ensure there is indeed an intentional blockade. If you are deliberately returning 403 codes for these URLs, you should withdraw them from the Google indexing request. These URLs should never be included in your sitemaps.
Solution Suggestion: Remove the URLs receiving this error through the URL removal process. Ensure they are not included in the sitemap.
Another 4xx Error
This error differs from the other 4xx error codes mentioned above and indicates an error that Google does not understand. If you encounter this coverage error, review the mentioned URL list. If these URLs indeed return 4xx error codes, ensure that Googlebots cannot access these URLs.
Solution Suggestion: You should be sure of how Google is accessing these URLs. Are these URLs listed in the sitemap? Are the error codes accurate? You must verify these points.
Comprehensive Resource on HTTP Status Codes: https://en.wikipedia.org/wiki/List_of_HTTP_status_codes
Duplicate Without a User-selected Canonical Page
This error occurs when there’s a duplicate version of a page without using the canonical tag. Encountering this error is a serious issue that requires swift action.
Solution Suggestion: Examine the URLs provided by Google. The version you prefer should be marked as the standard with the canonical tag across other URLs. Redirecting might also be considered.
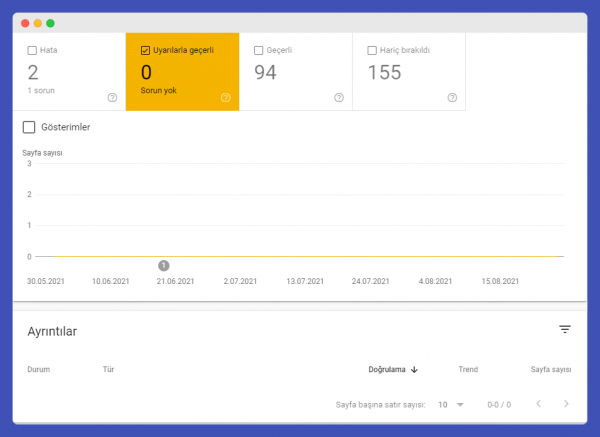
Google Search Console Coverage Warnings
Google Search Console coverage warnings indicate URLs that require attention and review within the index reports of Google Search Console. Pages under coverage warnings don’t fully fall into the error category, nor are they considered entirely valid. These pages might or might not have been added to the index. They definitely require a review. Coverage report warnings are divided into 2 categories:
Blocked by Robots.txt but Added to Index
URLs that have been added to the index despite being blocked by Robots.txt do not signify a serious issue. These URLs might have been linked from other websites, which is why Google could add these pages to the index despite the directives in robots.txt.
Solution Suggestion: Check these URLs and consider adding a noindex tag to them. After reviewing incoming links, you might proceed with link removal operations through the disallow tool.
Warned for Being Added to the Index Without Content
Pages under this warning have been added to the index. However, their content may not have been fully readable by Google. It’s important to ensure that these pages can be fully and clearly understood by Google. Formats can be checked, and the HTML structure can be reviewed.
Solution Suggestion: Check the page formats and HTML structure. Ensure that your page addresses do not receive any HTML errors by scanning them through W3 or similar tools.
Google Search Console Excluded Reports
Google Search Console index and coverage reports include “Excluded” reports, indicating URLs that have not been added to the index by Google’s decision. There is no error situation, but Google does not index these pages on its own initiative. There can be 15 different scenarios related to exclusion situations.
Excluded by Noindex Tag
This exclusion scenario originates from the same situation as the noindex error in coverage errors. Google does not consider the page being tagged as “noindex” an error, but still wants to inform site owners that it has been excluded.
Solution Suggestion: URLs affected by this situation should be checked. If noindex is not the desired status, action should be taken regarding the tags.
Page Blocked Due to URL Removal Tool
These excluded URLs are the ones that you have requested to be removed from the index using the “URL Removal” tool. Requests that are made and accepted are removed from the index for 90 days. After 90 days, if Google finds this page address from your sitemap, your internal links, or anywhere on the web and does not encounter a noindex tag, it can re-add it to the index.
Solution Suggestion: Ensure that the pages you have requested to be removed are not accessible from anywhere on your site. Add a noindex tag to these pages.
Blocked by Robots.txt
This warning is the same as the one in the coverage errors. The reason URLs blocked by Robots.txt are excluded is that, despite being blocked by Robots.txt, the Google bot can access these addresses through other means. For example, these pages may have been used in internal links or may have been included in the indexing process through a backlink. Also, despite being blocked by Robots.txt, the pages may not come as noindex.
Solution Suggestion: To remove these URLs from the excluded status, we must ensure that these addresses receive a noindex tag. Adding a noindex tag to these pages can largely solve the problem.
Crawled but Not Indexed
Pages excluded for this reason have been crawled but are seen by Google as not necessary to be indexed. This situation could be due to Google not considering the page to be of sufficient quality or suitable for indexing.
Solution Suggestion: You can try to strengthen your page’s content, making it quality content that provides value to the user.
Unauthorized Request
The unauthorized request error arises from the page returning a 401 code. Since the Google bot encounters a 401 barrier, it cannot index the page and excludes it. Discovery occurs but no crawl happens.
Solution Suggestion: Ensure that the page does not block the Google bot or Google bot IP addresses. If you do not want the page to be crawled, prefer to use the noindex tag. Remove it from the index.
Alternative Pages with a Proper Canonical Tag
Exclusions due to alternative page errors occur when another version or the original content has already been indexed by Google. That is, Google has determined the original pages among the repeating pages within your site and has only indexed those.
Solution Suggestion: No action is needed for this error. Google has already crawled and indexed the original URLs. However, canonical tag checks can still be performed.
Non-Unique Duplicate Pages
URLs excluded due to this error are perceived by Google as duplicate or similar content pages. Therefore, Google may crawl these pages but does not index and excludes them.
Solution Suggestion: This type of error generally stems from the absence of canonical tags. Check the duplicate or similar page URLs and tag the standard URLs with canonical tags.
Google Chose a Different Canonical URL
This error occurs when a URL you have designated as the canonical is not recognized as such by Google, and instead, Google selects a different canonical URL. The URL determined by Google is indexed.
Solution Suggestion: Use the standard URL determined by Google instead of the URL you designated as canonical. Apply this process to all URLs generating errors. If you believe there is a mistake, you can try to improve your content and resubmit a URL crawl request.
Not Found (404) Error
URLs excluded with a 404 error are those discovered by Google through means other than your sitemap or internal links, without a direct index request from you. These URLs might have been discovered through external links, so they will appear as excluded rather than errors.
Solution Suggestion: Ensure that this page does not receive external links. If the page has backlinks, use the link disavow tool.
Soft 404 Error
The Soft 404 error, also found in coverage errors, can appear in exclusions. These are URLs that, despite not being found and informing the user about it, return a successful HTTP code or do not return a 404 code.
Solution Suggestion: Review each URL marked as Soft 404. If they should return a 404 code but do not, add the code to correct the Soft URL status.
Submitted URL Not Selected as Canonical
This exclusion scenario arises when the URLs you requested to be indexed have duplicate or similar content, and no standardization has been made despite this. These URLs are perceived as copies of another page and are therefore excluded.
Solution Suggestion: Download this list of URLs and check for similarities or duplications with your content. Submit standardization processes by adding canonical tags to all these URLs, or if the URLs are of very low quality, consider redirection options directly.
Excluded Due to 403
URLs excluded due to a 403 error contain pages that have not been authorized. You may not have requested these pages to be indexed, but Google might still have accessed them. This results in the page being excluded.
Solution Suggestion: Mark pages returning a 403 code with a noindex tag and definitively add these pages to your robots.txt file.
Search Console Valid URL List
The “Valid URLs” section refers to URLs that have no errors and have been fully indexed by Google. There is no issue with these pages appearing in search results.
Indexed, Not Submitted in Sitemap
If you encounter the situation where a URL is indexed but was not submitted in the sitemap, the importance of the URL for the site should be assessed. If this URL is important and you want it to be indexed, you should consider why it was not added to the sitemap. If you are sure of its importance, the URL should be quickly added to the sitemap. It’s crucial to dynamically present our URLs open to indexing in the sitemap.
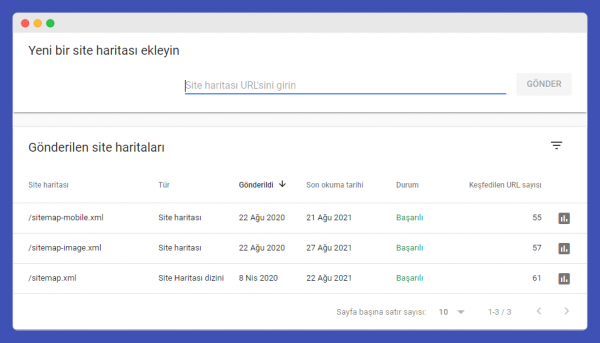
Google Search Console Sitemaps Section
The sitemaps section in the Search Console allows you to inform Google about the sitemaps you have created for your website, track the validity and errors of your sitemaps, and provides:
- The ability to add new sitemaps,
- The option to remove any sitemap you want,
- The capability to track errors in your sitemaps,
- Information on how many URLs in your sitemap are valid,
- The status of the sitemaps you have submitted,
- Information about the last crawl dates.
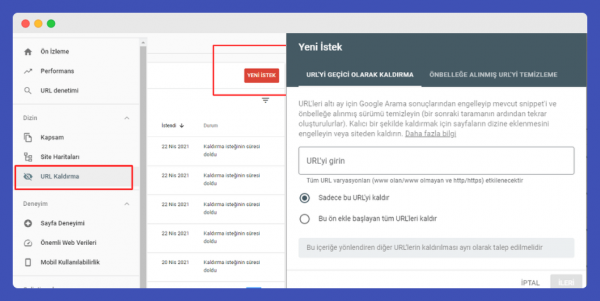
Google URL Removal Tool
The Google Search Console URL removal tool is a feature that allows you to request the removal of URLs that have previously been indexed by Google. Before using this tool, it’s crucial to be cautious and certain about the action. URLs removed using the URL removal tool will be excluded from the index for a period of 6 months. After 6 months, if these URLs are rediscovered, they can be added back to the index.
With the Google URL removal tool, you can either remove a specific URL or all URLs starting with a certain prefix in one go. Requests created with the Search Console URL removal tool are always kept in a list, allowing for retrospective checks and control.
How to Use Google URL Removal Tool?
To use the URL Removal tool in Google Search Console for removing URLs from the index, follow these steps:
- Open Google Search Console and navigate to the Index Reports section.
- Click on the URL Removal tool located under the Index Reports.
- Click on the “New Request” button that appears.
- Enter the URL you wish to remove in the required field.
- You then have the option to remove just this specific URL or all URLs that start with this prefix.
Why It’s Important to Check Index Reports to Optimise Google Crawl Budgets
Checking the index reports in Google Search Console is crucial for optimizing your site’s crawl budget for several reasons:
- Identification of Non-Beneficial URLs: Regularly reviewing the data in Google index reports helps identify URLs that should not be crawled and do not provide any benefit when crawled. Addressing these index errors and excluding non-beneficial URLs directly impacts the crawl budget by ensuring Google’s crawlers spend their resources on content that matters.
- Removal of 404 Error Pages: By removing URLs that return a 404 error from the index and preventing them from being recrawled, you free up crawl budget for more important pages on your site that need to be indexed or updated. This ensures that valuable site content has a higher chance of being crawled and indexed efficiently.
- Handling of Old and Redirected URLs: Managing old URLs and those that return a 301 redirect by preventing their recrawling and removing them from the index can significantly save crawl budget. This allows Google’s crawlers to focus on current and relevant content rather than wasting resources on outdated or permanently moved pages.
In summary, effectively managing your crawl budget through diligent monitoring and maintenance of index reports in Google Search Console helps improve your site’s visibility and indexing efficiency. This approach ensures that the most important content is prioritized for crawling and indexing, enhancing your site’s SEO performance.